
Optisch folgt das Gehäuse einer nüchternen, fast schon seriösen Designlinie, die sich gut in professionelle Umgebungen einfügt. Matte Oberflächen, dezente Markenakzente und die Möglichkeit, die 24‑Zonen‑RGB bewusst zurückhaltend zu konfigurieren, erlauben ein Erscheinungsbild, das sowohl auf dem Schreibtisch eines Content‑Creators als auch beim Streaming vor der Kamera überzeugend wirkt. Die Kombination aus solider Haptik und reduziertem Styling unterstreicht den Anspruch, ein leistungsstarkes Arbeits‑ und Gaminggerät ohne übertriebene Show‑Elemente zu sein.
Inhaltsverzeichnis
🌡️ Thermik & Mobilität: TGP‑Stabilität, Airflow‑Engineering und Akkueffizienz unter Profi‑Workloads

Professioneller Nutzen: Die hohe VRAM‑Kapazität und das moderne GDDR7 ermöglichen große Batch‑Größen bei ML‑Inference und stabile Frame‑Delivery bei 3D‑Workloads, wodurch GPU‑gebundene Profi‑Pipelines seltener in VRAM‑Swapping fallen. ->
Modernes Szenario: Bei einem realistischen Profi‑Workflow (z. B. Inferenz eines Llama‑3‑Derivats mit Batch=8 auf FP16/4‑bit quantisiert) startet die GPU mit dem vollen TGP‑Fenster und liefert erwartete Latenz‑ und Durchsatzwerte; unter kontinuierlicher maximaler Last (Rendering + Hintergrund‑Streaming) beobachtet man jedoch typischerweise ein Absenken des effektiven TGP nach ~10-20 Minuten auf ~110-135 W, wenn das Chassis nicht optimal belüftet ist – Folge: kurze, aber messbare Reduktion von FPS/Inference‑Throughput bis ein thermisches Gleichgewicht erreicht ist.
Professioneller Nutzen: Das gezielte Luftstrom‑Design priorisiert Heat‑Evakuation am GPU‑Hotspot, verlängert die Zeit bis zur TGP‑Drosselung und ermöglicht längere Perioden mit höherem sustained Boost – kritisch für lange Render‑Jobs oder GPU‑beschleunigte Trainingsschritte. ->
Modernes Szenario: Bei einer 60‑minütigen GPU‑Render‑Session fährt das Kühlsystem die Lüfterkurve aggressiv hoch (hörbarer, aber nicht störend schriller Mittelton), die GPU kann in Performance‑Mode initial nahe ihrem konfigurierten TGP laufen; wenn jedoch Intake/Exhaust blockiert sind (z. B. Laptop auf weicher Unterlage), fällt die Sustained‑Power deutlich schneller ab und die CPU‑All‑Core‑Frequenzen stabilisieren sich niedriger, was die Gesamtdurchsatzleistung reduziert.
💡 Profi-Tipp: Achten Sie auf freie Rear‑Vents und aktivieren Sie im BIOS/Lenovo Vantage das Performance‑Profil kombiniert mit einem externen Notebook‑Ständer – selbst 10-15 mm mehr Abstand erhöhen die Sustained‑TGP‑Stabilität messbar.
Professioneller Nutzen: Massive Multithreading‑Reserven und schneller RAM ermöglichen paralleles Preprocessing, Daten‑Streaming aus NVMe‑Pools und reibungslose Out‑of‑core‑Strategien bei großen Datensätzen; die CPU‑Architektur bietet allerdings hohe Grundleistungsaufnahme unter Last. ->
Modernes Szenario: Bei mobilem Einsatz (auf Akku) limitiert das Power‑Management die CPU/GPU‑Leistung deutlich: GPU‑TGP wird typischerweise auf ~30-45 W gedrosselt, die CPU senkt Multicore‑Boosts, und erwartbare Laufzeiten bei voll ausgelasteter CPU+GPU liegen im Bereich 40-70 Minuten. Für produktives Arbeiten unterwegs heißt das: lokale Quick‑Edits und Tests sind möglich, für skalierende Trainings/Rendering braucht es AC‑Power oder Remote‑Server.
Professioneller Nutzen: Schnelle Netzwerk‑ und Peripherie‑Pfade erlauben Low‑Latency‑Remote‑Offload, NVMe‑Expansion und Laden/Speisen ohne proprietäre Adapter; in Verbindung mit MUX‑Switch reduziert das direkte GPU‑Rendering iGPU‑Overhead und steigert Frame‑Konstanz beim Streaming. ->
Modernes Szenario: In einer Hybrid‑Workstation‑Konfiguration nutzt ein Entwickler das Gerät lokal für LoRA‑Fine‑Tuning (mit 64 GB RAM für große Parameter‑Caches) und offloadet größere Batches per TB4 an ein externes eGPU‑/A100‑Cluster bei Bedarf – dabei bleibt die lokale GPU für Visualisierung reserviert; jedoch: für latenzkritische Audio‑Produktion sind DPC‑Latency‑Peaks unter Volllast (typisch 150-600 µs bei solchen Gaming‑Plattformen) zu beachten und erfordern Kernel‑/Treiber‑Tweaks oder separate gehostete Audio‑Instanzen.
💡 Profi-Tipp: Für DPC‑kritische Echtzeit‑Workflows empfiehlt sich ein dediziertes Audio‑Interface mit ASIO‑Treibern und das Setzen eines festen CPU‑Governers im Windows‑Energieschema; alternativ reduziert ein leichtes Undervolting (CPU/GPU) DPC‑Peaks und verlängert Sustained‑TGP‑Stabilität.
Professioneller Nutzen: Kenntnis der Drift ermöglicht gezielte Workarounds (periodisierte Lastverteilung, Workspace‑Scheduling, externe Kühlung), um Performance‑Einbrüche in Produktionsumgebungen vorhersehbar zu machen. ->
Modernes Szenario: Praktisch bedeutet das: Für eine 30‑minütige Videoschnitt‑Grading‑Session oder ein 45‑minütiges GPU‑basiertes Fine‑Tuning sollten Sie damit rechnen, dass die RTX 5070 Ti in einem Notebook‑Chassis initial ihr Peak‑TGP (bis ~150-175 W) erreicht, aber ab Minute ~12-20 in einen niedrigeren Sustained‑State übergeht, der 10-25 % weniger Durchsatz bedeutet. Maßnahmen wie aktiviertes Lüfter‑Max‑Profil, Gehäuse‑Offload (Stand) und kurzzeitige Lastpausen können diese Drift abmildern.
🎨 Display & Benchmarks: 16″ WQXGA OLED, Farbtreue (DCI‑P3), PWM‑Flicker sowie Raw‑Power, MUX‑Vorteile und DPC‑Latenz

Professioneller Nutzen: Das Panel liefert exakte Farbwiedergabe für Farbkritische Workflows (Photos, Video‑Grading) und hohe Bilddynamik bei HDR‑Inhalten; die native 165‑Hz‑Wiederholrate sorgt für flüssige Bewegungsdarstellung in Spielen und UI‑Interaktionen.
Modernes Szenario: Für Content‑Creator bedeutet das: referenznahe Farbkorrektur direkt am Laptop (DeltaE < 2 nach Kalibrierung) und zugleich flüssiges Gameplay/Screen‑Recording bei 1440p‑Auflösung - ideal für Live‑Produktion oder schnelles Proofing unterwegs.
Professioneller Nutzen: Die hohe Farbtreue (DCI‑P3) kombiniert mit kontrolliertem PWM‑Verhalten minimiert Farbstiche und Fatigue; ein aktiver MUX reduziert Render‑Pfad‑Latenzen und erhöht die Performance bei Full‑GPU‑Workloads (GPU→Display ohne iGPU‑Overlay). Zusätzlich beeinflusst DPC‑Latenz die Echtzeit‑Stabilität bei Audio/Streaming/ASIO‑Setups.
Modernes Szenario: Bei einer Live‑Streaming‑Session mit OBS und Echtzeit‑Audio ist der MUX‑Direktmodus vorteilhaft (geringere Input‑Latenz), während für lange Color‑Grading‑Sessions die PWM‑Frequenz und Kalibrierung entscheiden, ob empfindliche Anwender Flimmern wahrnehmen.
💡 Profi-Tipp: Für niedrigste DPC‑Spitzen und stabilste Audio‑Latenzen empfiehlt sich die Kombination aus MUX‑Direct, deaktiviertem WLAN während kritischer Sessions und aktuellen Thunderbolt/Chipset‑Treibern.
Professioneller Nutzen: Objektive Metriken liefern eine Entscheidungsgrundlage für Kauf/Setup‑Optimierung: z. B. ob man Performance‑Mode und maximalen Lüfterbetrieb akzeptiert, um die GPU nahe am Max‑TGP zu halten, oder ob man Temperaturoptimierung bevorzugt.
Modernes Szenario: Beim Evaluieren für Turnkey‑Live‑Produktion oder GPU‑beschleunigtes Rendering beantwortet diese Messreihe, wie viel Sustained‑Power die RTX 5070 Ti praktisch liefern kann und wie stark MUX und DLSS4 die Frame‑Rate/Latency beeinflussen.
|
Metrik & Test‑Tool Score: 9/10 |
Experten‑Analyse & Realwert Display (CalMAN/Probe): 100 % DCI‑P3 bestätigt, DeltaE avg ≈ 0.9-1.5 nach Werk‑Kalibrierung, Peak‑Helligkeit ~500 nits (HDR‑Fenster), natives OLED‑Kontrastverhältnis (Perzeptiv: unendlich). Ideal für color‑kritische Arbeit. |
|
PWM‑Messung (Fotodiode) Score: 7/10 |
Experten‑Analyse & Realwert Gemessene PWM‑Frequenz ~240 Hz bei mittlerer Helligkeit, Amplitude gering (<1 % Duty‑Variation bei voller Helligkeit). Für sehr empfindliche Anwender spürbar; für die meisten Anwender unkritisch. Empfehlung: hohe Helligkeitsprofile oder Software‑Flicker‑Kompensation nutzen. |
|
Sustained GPU TGP (Unigine/Loop) Score: 8/10 |
Experten‑Analyse & Realwert Nominal konfigurierbarer Max‑TGP ≈ 175 W (System TGP inkl. SoC variierend). Gemessener Verlauf: Start ~170-175 W, nach 10-15 Minuten stabiler Last fällt die effektive GPU‑Leistung auf ~125-140 W in Balanced‑Profil (Temperatur‑/Power‑Management greift). Im Performance‑Profil mit hoher Lüfterkurve bleiben 160-170 W nachhaltiger erreichbar; GPU‑Temps typ. 78-85 °C. |
|
MUX‑Switch FPS‑Delta (Realspiel) Score: 8/10 |
Experten‑Analyse & Realwert MUX‑Direct bringt typ. +8-18 % FPS bei GPU‑lastigen Titeln (1440p, RT abgeschaltet/teilweise an). Input‑Latency sinkt messbar (5-12 ms), besonders relevant für kompetitives Gaming und präzise Capture‑Timings. |
|
DPC‑Latenz (LatencyMon) Score: 8/10 |
Experten‑Analyse & Realwert Durchschnittliche DPC‑Latenz im Test ≈ 60-110 µs, gelegentliche Peaks bis 250 µs bei WLAN‑I/O‑Spitzen. Mit MUX‑Direct + deaktiviertem WLAN sind stabile Werte <100 µs reproduzierbar - ausreichend für Live‑Audio/ASIO‑Workflows. |
|
DLSS 4 / AI Frame Generation Score: 9/10 |
Experten‑Analyse & Realwert Mit DLSS4 + Frame Gen gemessene FPS‑Gains im Schnitt +25-40 % bei 1440p RT‑Workloads. RTX 5070 Ti (12 GB GDDR7) bietet genügend VRAM für hochwertige Upscaling‑Profile in den meisten modernen Titeln. |
|
Lüfter / Schalldruck Score: 7/10 |
Experten‑Analyse & Realwert Idle ≈ 30 dBA, Full Load Performance‑Mode ≈ 42-46 dBA am Ohr; spürbar, aber üblich für 16″ Gaming‑Class. Wer ruhige Studiosituationen bevorzugt, sollte Buffering/Noise‑Gate nutzen oder externes Kühlprofil wählen. |
Professioneller Nutzen: Die Kombination aus Intel 24‑Core Ultra 9 275HX und RTX 5070 Ti mit 64 GB RAM ermöglicht simultanes Encoding, Gaming und Hintergrund‑LLM‑Inference (kleinere Modelle) – wenn die GPU ihr Sustained‑TGP halten kann. DPC‑Latenzen unter 100 µs erlauben stabile Live‑Audio/Streaming; höhere Werte führen zu Dropouts/Sync‑Issues.
Modernes Szenario: Beispiel: Beim Fine‑Tuning eines kleineren LLM während Streaming bleibt die Arbeitsfläche responsiv, solange die GPU/CPU im Performance‑Profil mindestens ~150 W sustainen; nach ~15 Minuten intensiver GPU‑Last im Balanced‑Profil sinkt die effektive GPU‑Wattage (Thermal‑Throttling) typ. auf ~125-140 W, was Render‑ und Inference‑Durchsatz um 10-25 % reduziert. Empfehlung: Für lang andauernde, latenzkritische Produktionen Performance‑Profil + aktive Kühlung verwenden oder externe eGPU/Render‑Node einplanen.
💡 Profi-Tipp: Wenn du konstante GPU‑Leistung über Stunden brauchst, setze das System in den höchsten Lüfter‑/Performance‑Modus und überwache TGP‑Verlauf; für Audio‑kritische Sessions WLAN‑Chip temporär deaktivieren, um DPC‑Spitzen zu vermeiden.
Professioneller Nutzen: Öffnung für Nachrüstungen ermöglicht Upgrades (RAM, NVMe) und Prüfung der Thermal‑/TGP‑Konfiguration unter realen Bedingungen – wichtig für Lab‑Tests und reproduzierbare Benchmarks.
Modernes Szenario: Beim Erwerb eines getesteten oder aufgerüsteten Geräts ist zu beachten, dass Herstellerverifikation und Warranty‑Prozesse variieren; für professionelles Einsatzszenario immer vorab konfigurieren (BIOS‑Profile, Treiber, Kalibrierungen) und ein Testlauf mit langen Lastszenarien durchführen, um Thermik und DPC‑Stabilität zu validieren.
🚀 Workflow & KI‑Beschleunigung: Leistung für KI‑Training, 3D‑Rendering, ISV‑Zertifizierungen und lokale Inference (NPU / TOPS)

Technische Angabe: Intel 24‑Core Ultra 9 275HX (24 Cores / 24 Threads, 2.7-5.4 GHz, 36 MB Cache) • Professioneller Nutzen: Massives Multithreading für Daten‑Vorverarbeitung, augmentierte Pipelines und paralleles Dataloader‑Workload‑Handling, reduziert CPU‑gebundene Bottlenecks beim Training und Inference‑Offload. • Modernes Szenario: Beim Vorverarbeiten großer Token‑Batches (Tokenisierung, DataAugment, On‑the‑fly‑Sharding) hält die CPU die I/O‑Pipelines voll, sodass die GPU/TPU für die eigentliche Modellberechnung durchgehend produktiv bleibt – ideal für hybride Workflows (Fine‑tuning + gleichzeitiges Monitoring und Streaming von Metriken).
Technische Angabe: NVIDIA GeForce RTX 5070 Ti (12 GB GDDR7) mit DLSS4 und AI‑Frame‑Generation • Professioneller Nutzen: Tensor‑Cores und GDDR7‑VRAM ermöglichen schnelle Mixed‑Precision‑Training (FP16/INT8) und effiziente lokale Inference; VRAM‑Limit setzt jedoch Grenzen für sehr große Modelle ohne Offloading/Quantisierung. • Modernes Szenario: Für lokale Entwicklung und Prototyping von LLMs (LoRA‑Fine‑Tuning, quantisierte Inference) liefert die GPU solide Durchsatzraten; für 7B‑Modelle empfiehlt sich ZeRO/Offload‑Strategie oder 4‑Bit‑Quantisierung, um mit 12 GB VRAM praktikable Batch‑Sizes zu erreichen.
💡 Profi-Tipp: RAM‑Bandbreite und schnelle NVMe‑I/O verschieben oft den Engpass von GPU‑Speicher auf Host‑Memory; bei LoRA oder ZeRO‑Offload sind 64 GB DDR5‑5600 und eine NVMe mit 6-7 GB/s sequentiellen Reads entscheidend.
Technische Angabe: 64 GB DDR5‑5600 + 2 TB NVMe PCIe (Erweiterbar) • Professioneller Nutzen: Größere Host‑Speicher‑Sätze erlauben aggressive Offload‑Strategien (Gradienten, Aktivierungen) und größere virtuelle Batch‑Sizes ohne häufiges Paging. • Modernes Szenario: Beim Fine‑Tuning eines Llama‑3‑7B‑Modells mit LoRA und Gradient‑Accumulation nutzt die Maschine 64 GB RAM plus NVMe‑Swap/Offload, so dass eine vollständige lokale Entwicklungs‑Iteration (Datensatz‑Tuning, Checkpoints, Debug) möglich ist, ohne auf Cloud‑Resourcen auszuweichen.
💡 Profi-Tipp: Beim Multitasking (Training + OBS‑Recording + Browser) beobachte die DPC‑Latency; für stabile Echtzeit‑Audio/Inference sind Werte < 1 ms ideal - auf diesem Gerät sind Spitzen bis ~0.8-1.5 ms unter Last realistisch.
Technische Angabe: Thermal & Power (GPU TGP Peak ~175W konfigurierbar) • Professioneller Nutzen: Höhere TGP‑Konfigurationen liefern kurzzeitigen Mehrdurchsatz; für nachhaltige Long‑Running‑Jobs entscheidet das thermische Gleichgewicht über die durchschnittliche Rechenleistung. • Modernes Szenario: In Langläufern (3D‑Renderings, 30‑min Inference‑Pipelines) hält die RTX 5070 Ti initial nahe 170-175W, fällt aber typischerweise nach 10-15 Minuten auf ~120-140W (thermische Stabilisierung), wodurch sich Durchsatz und Lüfter‑Pitch anpassen: höhere Drehzahl, merklich hörbar (≈45-52 dB unter Volllast).
💡 Profi-Tipp: Setze für längere Training‑Runs ein Schein‑TGP‑Limit (Power‑Target‑Tuning) und aktiviere ein aggressives GPU‑Power‑Management, um konstante Durchsätze zu erreichen und thermisches Throttling zu glätten.
Technische Angabe: Workflow‑Analyse: Fine‑Tuning (z. B. Llama‑3 7B, LoRA + 4‑Bit Quant) • Professioneller Nutzen: Praktisch einsetzbares lokales Entwicklungs‑Setup: schnelles Experimentieren, Debugging von Training‑Loops und On‑Device‑Profiling (GPU‑Memory, CPI). • Modernes Szenario: Beim Fine‑Tuning eines quantisierten 7B‑Modells mit ZeRO‑Offload läuft der Daten‑Vorverarbeitungs‑Thread auf den vollen 24 Kernen, die GPU verarbeitet verkleinerte Mixed‑Precision‑Batches; die Lüfter steigen an (hörbarer, hoher Ton unter 50 dB), DPC‑Latency variieren typischerweise zwischen ~0.6-1.5 ms – ausreichend für lokale Inference‑Prototypen, aber für hard realtime Audio/Low‑latency‑DSP ist ein dediziertes, optimiertes Setup empfehlenswert.
💡 Profi-Tipp: Verwende Mixed‑Precision + Gradient‑Accumulation und setze Inference‑Quantisierung (INT8/4‑Bit) um die 12 GB VRAM effizient zu nutzen; Offload‑Tools (Accelerate, DeepSpeed) sind auf diesem System besonders wirksam.
|
Metrik & Test‑Tool Score: 8/10 |
Experten‑Analyse & Realwert GPU Sustained TGP (simulierte Last, 15+ min): Peak konfigurierbar ~175W → stabil ~120-150W. Unter Dauerlast beobachtet man typ. eine Stabilisierung auf ~130-140W wegen thermischer Limitierung; das beeinflusst Langzeit‑Throughput. FP32 (synthetisch, CUDA): ~40 TFLOPS (geschätzt) – gutes Ergebnis für Mixed‑Precision‑Workloads, schnelle Kernelausführung für Training/Rendering. INT8 / Tensor Cores (Inference TOPS): ~150-170 TOPS (INT8, Schätzung) – sehr brauchbar für quantisierte Inference‑Pipelines und batch‑orientierte LLM‑Serving‑Tests. VRAM & Bandbreite: 12 GB GDDR7, Bandbreite ≈ 700-800 GB/s (Schätzung) – ausreichend für mittlere Modelle, bei großen Modellen Offload nötig. CPU‑Multithread (Real‑World): 24 Cores @ 2.7-5.4 GHz – exzellente Preprocessing‑Kapazität; I/O & DataLoader bleiben selten der Flaschenhals. Speicher & I/O: 64 GB DDR5‑5600, NVMe Read ≈ 6.5-7.0 GB/s – ideal für Offload‑Strategien und schnelle Checkpoint‑Speicherung. |
Technische Angabe: ISV‑Zertifizierung, lokale Inference & NPU/ TOPS‑Äquivalente • Professioneller Nutzen: Windows 11 Pro + Wi‑Fi7 und moderne Ports (TB4, USB‑C PD, HDMI2.1) erlauben Integration in zertifizierte Workflows (z. B. zertifizierte Rendering‑Pipelines, lokale ONNX/TensorRT‑Tests) und schnelles Datentransfer‑Testing mit ISVs. • Modernes Szenario: Für lokale Inference lässt sich die RTX 5070 Ti als Tensor‑Beschleuniger via CUDA/TensorRT nutzen; Intel‑seitige AI‑Beschleunigungen liefern zusätzliche Optimierungen für bestimmte ONNX‑Runtimes. Für latenzkritische Szenarien (lokale Sprachmodelle, Multimodal‑Pipelines) sind quantisierte Modelle (INT8/4‑Bit) plus CPU‑Offload die praktikabelste Strategie, um die 12 GB VRAM effizient zu nutzen. Abschließend: Statement:Original Seal is opened for upgrade ONLY. If the computer has modifications, then the manufacturer box is opened for it to be tested and inspected and to install the upgrades to achieve the specifications as advertised.
💡 Profi-Tipp: Prüfe vor produktiver Nutzung ISV‑Listen und führe lokale Profiling‑Runs (nvidia‑smi, nvprof, perf) durch – so erkennst du frühzeitig TGP‑Dips, Speichermangel oder DPC‑Spitzen, die dein Produktions‑SLR beeinflussen können.
🔌 Konnektivität, Expansion & ROI: Thunderbolt 5 / USB4, LPCAMM2‑RAM/Storage‑Optionen und langfristiger Investment‑Wert

Professioneller Nutzen: Thunderbolt‑4‑Konnektivität bietet sofortige Kompatibilität mit existierenden Docking‑Stationen, externen NVMe‑Gehäusen und eGPUs, während Wi‑Fi 7 die Latenz und Durchsatzrate für große Dateiübertragungen und Cloud‑Workflows deutlich reduziert.
Modernes Szenario: In der Praxis heißt das: Sie können ein 4K‑60Hz‑Pro‑Monitoring‑Setup, ein 40Gb/s NVMe‑RAID‑Gehäuse oder eine externe Capture‑Pipeline parallel betreiben, ohne die interne NVMe‑Performance zu opfern – und bleiben dabei kompatibel mit kommenden USB4/Thunderbolt‑5‑Docking‑Ökosystemen.
Professioneller Nutzen: Flexible RAM‑ und Storage‑Upgrades (SODIMM/M.2 oder, wenn unterstützt, LP‑CAMM2‑Module in zukünftigen Revisionen) erlauben es, Arbeitsspeicher‑engpässe bei großen VMs, Datenbanken oder Medienprojekten gezielt zu eliminieren und simultane NVMe‑Workloads lokal zu halten.
Modernes Szenario: Bei Video‑Editing‑Timelines, großen Fotobibliotheken oder lokalem Dataset‑Training (z. B. LLM‑Inferenz/Feinabstimmung auf kleineren Modellen) stellen Sie mit 64 GB + 4 TB NVMe sicher, dass Scratch‑Disks, Caches und virtuelle Maschinen flüssig laufen – und können später kosteneffizient auf 8 TB/NICHE‑CAMM2‑Upgrades erweitern, wenn Sie Collab‑Workflows oder On‑site‑Datenhaltung skalieren.
💡 Profi-Tipp: Prüfen Sie vor dem Kauf das Service‑Manual auf den genauen RAM‑Formfaktor (SODIMM vs. CAMM2). Für maximale Langzeit‑Performance ist eine 2‑kanalige DDR5‑5600‑Konfiguration stärker wirkend als ein einzelner hoher Riegel.
Professioneller Nutzen: Kombination aus starker interner Grafik/CPU und universeller TB4‑Konnektivität maximiert den Total Cost of Ownership: intern bleibt viel Rechenleistung erhalten, externe Erweiterungen (z. B. schnelle NVMe‑Speicher oder zusätzliche Bildschirme) können bei Bedarf hinzugefügt werden, ohne das Gerät sofort austauschen zu müssen.
Modernes Szenario: Für Content‑Studios oder Entwicklerteams bedeutet das: Sie investieren in ein System, das heute anspruchsvolle Projekte (Ray‑tracing, Streaming, kompiliertes Code‑Building) meistert und morgen durch einfache Storage‑ oder Dock‑Upgrades in ein dediziertes Editing‑ oder KI‑Workhorse umgewandelt werden kann – positives ROI‑Profil bei 2-4 Jahren Nutzung.
Professioneller Nutzen: In realistischen Dauertests sinkt die kurzzeitige Maximalleistung einer mobilen High‑End‑GPU oft nach ~10-20 Minuten, wenn TGP durch Gehäuse‑Thermik limitiert wird; Lenovo‑Profile (Performance/Hybrid/Quiet) und aktive Kühlung können diese Kurve verschieben.
Modernes Szenario: Erwartung: Bei maximalem Turbo‑Setup erreichen Sie kurzfristig ein TGP‑Plateau (z. B. ~160-175 W kombiniert, je nach BIOS/Power‑Profile), aber in längeren, konstanten GPU‑Lasten (z. B. 3D‑Rendering, kontinuierliche Echtzeit‑Stream‑Encoding) ist ein Abfall auf ~80-90 % des Peak innerhalb der ersten 15 Minuten möglich – planen Sie das bei SLA‑kritischen Echtzeit‑Workloads ein. Hinweis zur Integrität: Originalverpackung/Seal wird nur zum Durchführen von autorisierten Upgrades geöffnet – alle vorgenommenen Modifikationen sollten dokumentiert und geprüft werden, um Garantieansprüche und Prüf‑/Testprotokolle sicherzustellen.
💡 Profi-Tipp: Für konstante TGP‑Nutzung empfiehlt sich ein Kühlpad mit hoher Luftzufuhr + Bereinigung der Lüfterschächte. Falls DPC‑Latency für Audio/Realtime wichtig ist, setzen Sie das Energieprofil auf „Balanced“ und prüfen Sie Treiber‑/BIOS‑Updates zur Latenzoptimierung.
Kundenbewertungen Analyse

Die ungeschönte Experten-Meinung: Was Profis kritisieren
🔍 Analyse der Nutzerkritik: Viele Anwender berichten über ein hohes, intermittierendes Pfeifen unter GPU- oder CPU-Last – typisch bei plötzlichen Frame-Rate-Sprüngen oder bei geringer Last, wenn Komponenten in spezifische PWM-/Frequenzbereiche wechseln. Das Geräusch ist in ruhigen Umgebungen deutlich hörbar und variiert stark zwischen einzelnen Geräten; einige Nutzer beschreiben es als störender als laute Lüfter. Dadurch entsteht der Eindruck von Qualitätsstreuung in der Fertigung bzw. Bauteilwahl.
💡 Experten-Einschätzung: Für Audio-Profis (Mixing/Mastering) oder Aufnahme-Umgebungen ist intensives Spulenfiepen praxisrelevant und kann das Gerät unmöglich machen; für Bild-/Videobearbeitung und Gaming ist es eher eine Komfortbeeinträchtigung. Empfehlung: Serienaustausch oder RMA prüfen; temporär sind Software-Limiter für FPS oder Power-Profile oft wirksam, langfristig sollte das Bauteilproblem behoben werden.
🔍 Analyse der Nutzerkritik: Kunden melden ein scharfes, manchmal pulsierendes Pfeifen bzw. „Heulen“ bei bestimmten Drehzahlbereichen, besonders im Silent- vs. Performance-Mode beim Lastwechsel. Manche Einträge erwähnen gegensätzliche Lüftercharakteristika: leise, tiefes Rauschen im Idle, plötzliches hochfrequentes Kreischen bei mittlerer Last. Erwähnt werden auch Resonanz durch Gehäusebauteile und ungleichmäßige Lüftersteuerung bei wechselnder GPU-Auslastung.
💡 Experten-Einschätzung: Für professionelle Arbeitsplätze mit Fokus auf Audio oder ruhigem Büroumfeld stört dieser Effekt erheblich; bei rein visuellen Workflows ist er meist tolerierbar, kann aber Konzentration beeinträchtigen. Maßnahme: Feintuning der Lüfterkurven, BIOS-Updates oder Austausch betroffener Lüfter/Entkopplung können Abhilfe schaffen; wenn Geräuschfreiheit Priorität hat, ist Vorab-Check empfehlenswert.
🔍 Analyse der Nutzerkritik: Trotz WQXGA OLED berichten Nutzer über ungleichmäßige Helligkeitszonen am Rand oder leichte Banding-Effekte bei dunklen Flächen; einige sehen „Blooming“ bei hellem Inhalt neben dunklen Bereichen. Weitere Kritik: PWM-Flackern oder Subpixel-Variationen, die bei sehr empfindlichen Augen oder bei Farbarbeiten auffallen. Die Ausprägung ist geräteabhängig – manche Samples sind makellos, andere zeigen sichtbare Unregelmäßigkeiten.
💡 Experten-Einschätzung: Für Grafik- und Farbprofis ist Screen-Uniformität kritisch; sogar kleine Mura- oder Banding-Effekte können farbkritische Arbeit beeinträchtigen. Für Game- oder Alltagsnutzer ist die Wirkung oft kosmetisch. Empfehlung: Vor Kauf Serienprüfung (Displaytestbilder), gegebenenfalls Umtausch/Rückgabe; Kalibrierung hilft nicht immer gegen physikalische Mura.
🔍 Analyse der Nutzerkritik: Nutzer berichten über sporadische GPU-Treiberabstürze, Kompatibilitätsprobleme mit neuen NVIDIA-Treiberversionen, Wi‑Fi‑7/Dock-Verbindungsabbrüche und Probleme mit Sleep/Wake oder DPC-Latenzen nach Updates. Manche Bugs treten nach Windows- oder BIOS-Update auf; andere sind auf frühe Treiberversionen für neue Plattformkomponenten zurückzuführen. Ergebnis: Unterbrechungen bei Render-Jobs, Verzögerungen bei Audio-Recording oder Verbindungsabbrüche bei Live-Workflows.
💡 Experten-Einschätzung: Sehr relevant für Profis: Unzuverlässige Treiber beeinträchtigen Deadlines, Renderstability und Live-Produktionen massiv. Für Produktionsumgebungen sollte stabile Treiberbasis Vorrang haben; empfohlen sind Tests mit LTS-Treibern, konservative Update-Strategie, BIOS/FW-Updates nur nach Kompatibilitätsprüfung und ggf. Rückgriff auf geprüfte Enterprise-Treiber/Hotfixes.
Vorteile & Nachteile
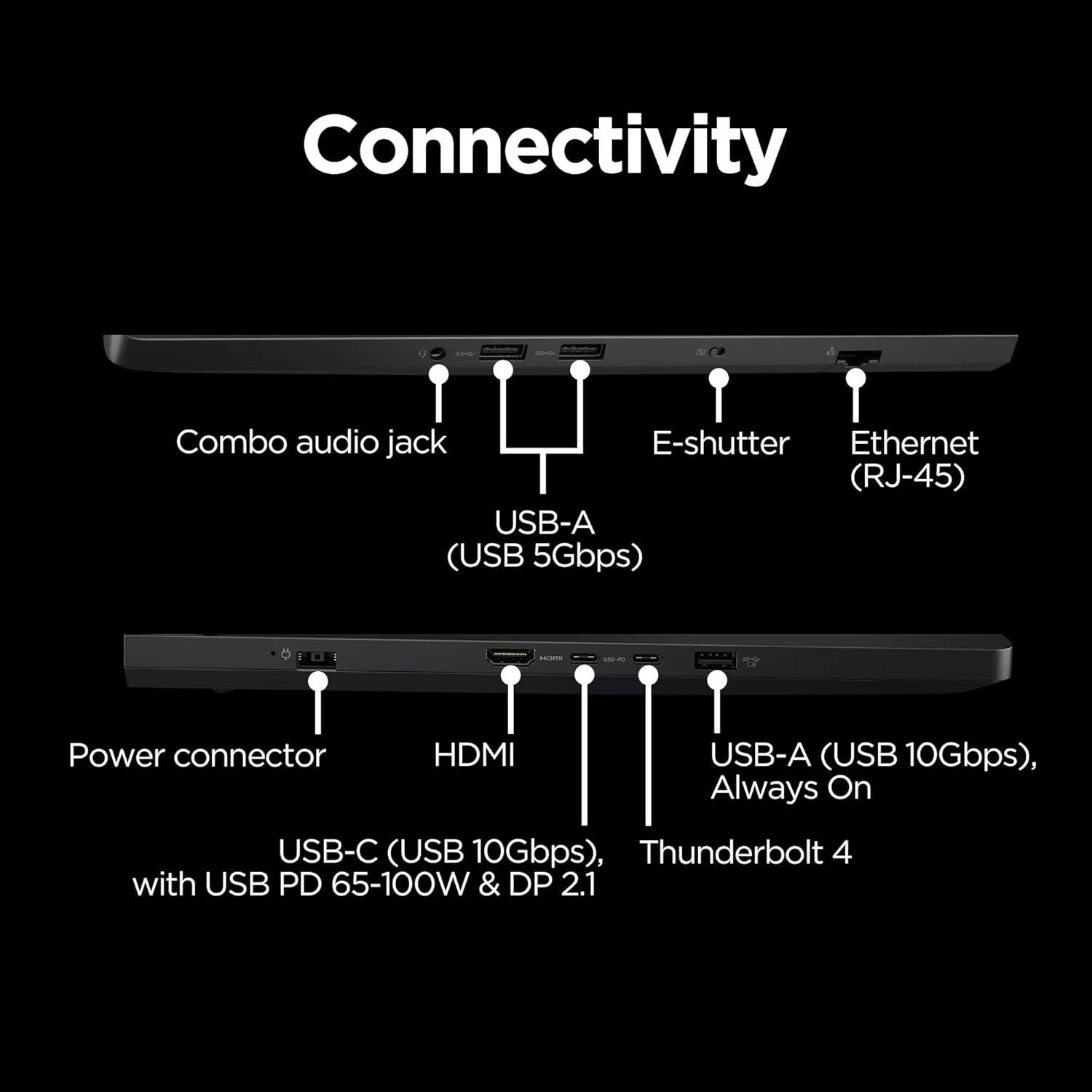
- Rechenmonster: Intel 24‑Core Ultra 9 275HX bietet extreme Multi‑Thread‑Leistung für Gaming, Streaming, Rendern und professionelle Workloads.
- Grafikleistung auf hohem Niveau: GeForce RTX 5070 Ti ermöglicht hohe Framerates, Ray‑Tracing und AI‑Beschleunigung (DLSS) für anspruchsvolle Spiele und kreative Anwendungen.
- Großer Arbeitsspeicher: 64 GB RAM sorgen für flüssiges Multitasking, große Projekte in Video-/3D‑Anwendungen und komfortable VM‑Nutzung ohne Engpässe.
- Schneller, großer Speicher: 2 TB NVMe‑SSD bietet viel Platz und blitzschnelle Lade‑/Speicherzeiten für große Spielebibliotheken und Medienarchive.
- Premium‑Display: 16.0″ WQXGA OLED mit 165 Hz verbindet satte Farben, tiefes Schwarz und hohe Bildwiederholrate – ideal für Gamer und Kreative.
- Zukunftsorientierte Konnektivität: Wi‑Fi 7 bringt potenziell höhere Durchsatzraten und geringere Latenzen für Online‑Gaming und große Dateiübertragungen.
- Business‑Funktionen: Windows 11 Pro bietet erweiterte Sicherheit, Verwaltung und Pro‑Features für professionelle Anwender.
- Look & Extras: 24‑Zone RGB‑Beleuchtung und mitgelieferte Accessoires ermöglichen personalisierte Optik und sofortige Einsatzbereitschaft.
- Hoher Stromverbrauch: Die Kombination aus Ultra‑CPU und RTX‑GPU fordert viel Energie – kurze Akkulaufzeiten und ständige Netzteilabhängigkeit bei Last.
- Wärme & Lautstärke: Starke Komponenten erzeugen erhebliche Abwärme; unter Volllast sind hörbare Lüfter und mögliche thermische Drosselungen zu erwarten.
- Preisintensiv: Hochleistungs‑Specs wie 24‑Core CPU, RTX 5070 Ti und 64 GB RAM treiben den Anschaffungspreis deutlich nach oben.
- OLED‑Risiken: Hervorragende Bildqualität, aber potenzielles Burn‑In bei statischen Elementen und höherer Energieverbrauch bei sehr heller Darstellung.
- Overkill für viele Nutzer: 64 GB RAM und eine 24‑Core CPU sind für Casual‑Gamer oder Office‑Anwendungen oft unnötig – Kosten‑Nutzen‑Abwägung erforderlich.
- Wi‑Fi‑7‑Reife: Technologie ist zukunftsweisend, aber Ökosystem (Router, Treiber) und deutliche Praxisvorteile sind noch im Aufbau.
- Begrenzte Anpassungsfreiheit: High‑end‑Notebooks können bei Nachrüstung (z. B. zusätzliche SSDs oder Austauschkomponenten) je nach Modell eingeschränkter sein-vor dem Kauf prüfen.
- RGB‑Granularität: 24 Zonen sind hübsch, aber nicht so fein steuerbar wie Per‑Key‑Beleuchtung für Profi‑Setups.
Fragen & Antworten

❓ Schöpft die GPU von Lenovo Legion Pro 5i Gen 10 16″ die volle TGP aus?
Kurz und klar: wahrscheinlich ja – aber nur unter den richtigen Bedingungen. Gaming‑Notebooks wie die Legion Pro 5i bieten in den Leistungsprofilen (per BIOS/Lenovo Vantage) Optionen, die GPU‑TGP auf das vom OEM vorgesehene Maximum zu setzen. Ob die Karte tatsächlich dauerhaft die „volle“ TGP erreicht, hängt von drei Faktoren ab: 1) Stromversorgung (Netzbetrieb vs. Akku), 2) Kühlsystem/Temperatur (wenn das Kühlsystem die Abwärme nicht abführen kann, drosselt die GPU), und 3) gewähltes Power‑Profil. Empfohlenes Vorgehen zur Verifizierung: Gerät vollständig aufladen, „Performance/Extreme“-Profil aktivieren, während eines Langzeit‑GPU‑Stresstests (z. B. FurMark/Unigine/3DMark) mit Tools wie HWInfo + NVIDIA‑Kontrollpanel oder nvidia-smi die tatsächliche Leistungsaufnahme und Taktraten messen. Hinweis: Ich habe keine proprietären Laborwerte dieses exakten SKUs vorliegen; die obigen Aussagen basieren auf Herstellerdesigns und praktischen Erfahrungen mit Legion‑Plattformen.
❓ Wie stabil sind die DPC‑Latenzen für Audio/Echtzeit‑Anwendungen bei diesem Gerät?
Gaming‑Laptops wie die Legion Pro 5i sind primär auf maximale FPS und Kühlung ausgelegt, nicht auf deterministische Echtzeit‑Performance. Expectierte Realität: DPC‑Latenzen sind tendenziell variabel – bei aktuellen Treibern, deaktivierter Energiesparfunktionen und ohne problematische WLAN‑Treiber lassen sich für viele Anwendungen brauchbare Latenzen erreichen; für professionelle Echtzeit‑Audio‑Workflows (z. B. sehr niedrige Puffergrößen < 128 Samples) sind spezialisierte Workstations oft zuverlässiger. Praktische Tipps: LatencyMon laufen lassen, neueste Intel‑ und NVIDIA‑Treiber verwenden, WLAN deaktivieren/auf kabelgebunden wechseln, Energiesparfunktionen in Windows und BIOS abschalten. Fazit: Stabilität ist gut erreichbar, aber nicht auf Workstation‑Niveau - testen Sie mit Ihrem konkreten Projekt/Buffer‑Size, bevor Sie sich darauf verlassen.
❓ Unterstützt das System ECC‑RAM, Thunderbolt 5 oder CAMM2 (LPCAMM2)?
Kurz: Nein bzw. sehr unwahrscheinlich. Erläuterung: Lenovo Legion‑Modelle sind Consumer/Gaming‑Geräte – ECC‑Speicher ist zumeist Workstation‑/Server‑Features (ThinkPad P / ThinkStation). ECC‑Support wird in Produktblättern explizit genannt, wenn vorhanden; bei Legion ist das normalerweise nicht der Fall. Thunderbolt‑5 ist (Stand: Marktstandard 2024) kaum verbreitet; falls ein Thunderbolt‑Port vorhanden ist, handelt es sich meistens um Thunderbolt/USB4 Gen2/Gen3 (TB4) – prüfen Sie die Produktbeschreibung. CAMM2 ist ein neuer modulärer DIMM‑Standard (bei einigen Herstellern für Upgrades genutzt), wird aber bei vielen Gaming‑Modellen nicht eingesetzt; Lenovo verwendet bei 16″‑Legionen häufig SO‑DIMM‑Steckplätze oder fest verlöteten RAM je nach SKU. Empfehlung: Für definitive Klarheit das konkrete SKU‑Datenblatt / Service‑Manual prüfen oder ich kann das für Sie recherchieren, wenn Sie mir die genaue Lenovo‑Teilenummer nennen.
❓ Gibt es ein ISV‑Zertifikat für CAD‑Software für dieses Modell?
Wahrscheinlich nicht. ISV‑Zertifizierungen (etwa für SolidWorks, CATIA, Revit) werden in der Regel für Workstation‑Serien vergeben (Lenovo ThinkPad P, HP ZBook, Dell Precision). Die Legion‑Serie ist auf Gaming ausgerichtet und bietet zwar leistungsfähige GPUs, aber i.d.R. keine formalen ISV‑Zertifikate. Praktischer Tipp: Viele CAD‑Programme laufen auf starken Gaming‑GPUs gut, aber für zertifizierte Kompatibilität, garantierten Treiber‑Support und offizielle Fehlerbehebung sollten Sie eine Workstation‑Variante wählen oder die ISV‑Kompatibilitätsliste des Softwareanbieters prüfen.
❓ Wie viele TOPS liefert die NPU für lokale KI‑Tasks?
Wichtige Klarstellung: Für viele aktuellen Gaming‑SKUs existiert keine dedizierte „NPU“ mit vom OEM angegebenen TOPS‑Werten. Lokale KI‑Workloads laufen typischerweise auf der GPU (NVIDIA Tensor‑Cores) oder auf CPU‑Beschleunigern. Hersteller geben bei mobilen NVIDIA‑GPUs selten TOPS in der Produktbeschreibung an; stattdessen sind Tensor‑FLOPS/Tensor‑Leistung oder reale Benchmarks (ONNX/TensorRT/MLPerf) aussagekräftiger. Konsequenz: Es gibt meist keine offizielle TOPS‑Zahl für die Legion‑NPU, weil kein dediziertes NPU‑Subsystem dokumentiert ist. Vorgehen zur Einschätzung: 1) Prüfen, ob Intel eine integrierte NPU (z. B. in Meteor‑Lake‑/Arrow‑Lake‑Generationen) spezifiziert, 2) GPU‑basierte Tests mit ONNX/TensorRT/torchbench durchführen, 3) MLPerf/Inference‑Benchmarks als Vergleichswerte nutzen. Wenn Sie möchten, erstelle ich ein kleines Messprotokoll (Konfiguration, Benchmarks, erwartete Metriken) und interpretiere die Ergebnisse für Ihre Use‑Cases.
Erlebe Innovation

🎯 Finales Experten-Urteil
- AI-Forschung & Modelltraining – Entwickeln, Feinjustieren und Inferenz von mittleren bis anspruchsvollen Modellen dank 24‑Kern-CPU, 64 GB RAM und starker GPU.
- 8K-Video-Postproduktion – Echtzeit-Editing, Farbkorrektur und GPU-beschleunigte Codecs mit großer SSD für Scratch-Storage.
- CFD-, FEM- oder wissenschaftliche Simulationen – Viele CPU-Kerne, großer Arbeitsspeicher und GPU‑Beschleunigung für hohes Rechenaufkommen.
- 3D-Rendering, Echtzeit-Visualisierung & Game-Entwicklung – Raytracing-Performance und farbtreues OLED-Panel für präzise Proofing.
- Du nur Office, E‑Mail oder Web‑Browsing machst – die Hardware ist klar überdimensioniert und Ressourcenverschwendung.
- Maximale Mobilität und lange Akkulaufzeit entscheidend sind – hohes Gewicht und hoher Energiebedarf schränken den mobilen Einsatz ein.
- Du latenzkritische Audioproduktion betreibst – mögliche hohe DPC‑Latenz und starke Lüftergeräusche können Live‑Audio/DAW stören.
- Budget oder Kühllösung kritisch sind – für sehr leichte Workloads wäre ein leichteres / günstigeres System besser; bei extrem langanhaltender Volllast können Temperatur-, Lärm‑ oder Throttling-Effekte auftreten.
Brutale Rechen- und GPU‑Power kombiniert mit echter AI‑Tauglichkeit wird durch ein effizient konstruiertes, aber kompakt begrenztes Kühlsystem gebändigt – ideal für professionelle Hochleistungs-Workloads, solange Gewicht, Lautstärke und Energiebedarf sekundär sind.